
前言:
授人以鱼不如授人以渔,大家在编程的时候总会遇到要查找某些复杂规则的字符串,例如在 linux 系统中,需要对多个文件里的某段代码进行替换,你是不是还在每个文件打开逐一目标替换?如果你也有这样的困惑那么正则表达式就是你必须会的技能。
推荐一个github的程序员资料仓库:
1、什么是正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个 “规则字符串” ,这个 “规则字符串” 用来表达对字符串的一种过滤逻辑。换句话说,正则表达式就是记录文本规则的代码。
很可能你使用过 Windows 下用于文件查找的通配符(wildcard),也就是 * 和 ?。如果你想查找某个目录下的所有的 pdf 文档的话,可以直接搜索 *.pdf,如下:

在这里,* 会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求。当然,代价就是更复杂,比如你可以编写一个正则表达式,用来查找所有以 0 开头,后面跟着 2-3 个数字,然后是一个连字号 “-” ,最后是 7 或 8 位数字的字符串(像 011-12345678 或 0856-7654321)。
2、入门
学习正则表达式的最好方法是从例子开始。
- 假如你在一篇英文期刊里查找 me,你可以使用正则表达式 me。
这几乎是最简单的正则表达式了,它可以精确匹配这样的字符串:由两个字符组成,前一个字符是 m, 后一个是 e。通常,处理正则表达式的工具会提供一个忽略大小写的选项,如果选中了这个选项,它可以匹配 me, ME, Me, mE 这四种情况中的任意一种。
不幸的是,很多单词里包含 hi 这两个连续的字符,比如 me, mean, measure等等。用 me 来查找的话,这里边的 me 也会被找出来。如果要精确地查找 me 这个单词的话,我们应该使用 bmeb。
b 是正则表达式规定的一个特殊代码(有些人叫它元字符,metacharacter),代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是 b 并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。
- 假如你要找的是 me 后面不远处跟着一个 james,你应该用 bmeb.*bjamesb。
这里 . 是另一个元字符,匹配除了换行符以外的任意字符。* 同样是元字符,不过它代表的不是字符,也不是位置,而是数量——它指定 * 前边的内容可以连续重复使用任意次以使整个表达式得到匹配。
因此 .* 连在一起就意味着任意数量的不包含换行的字符。现在bmeb.*bjamesb的意思就很明显了:先是一个单词 me 然后是任意个任意字符(但不能是换行),最后是 james 这个单词。
3、元字符
正则表达式由一些普通字符和一些元字符(metacharacters)组成。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义,要想真正的用好正则表达式,正确的理解元字符是最重要的事情。下表列出了常用的元字符

4、字符转义
如果想查找元字符本身的话,比如查找 . ,或者 * ,就出现了问题:你没办法指定它们,因为它们会被解释成别的意思。这时就得使用 来取消这些字符的特殊意义。因此,应该使用 . 和 *。当然,要查找 本身,也得用 。
例如:mayday.net 匹配 mayday.net ,C:\Windows匹配C:Windows。
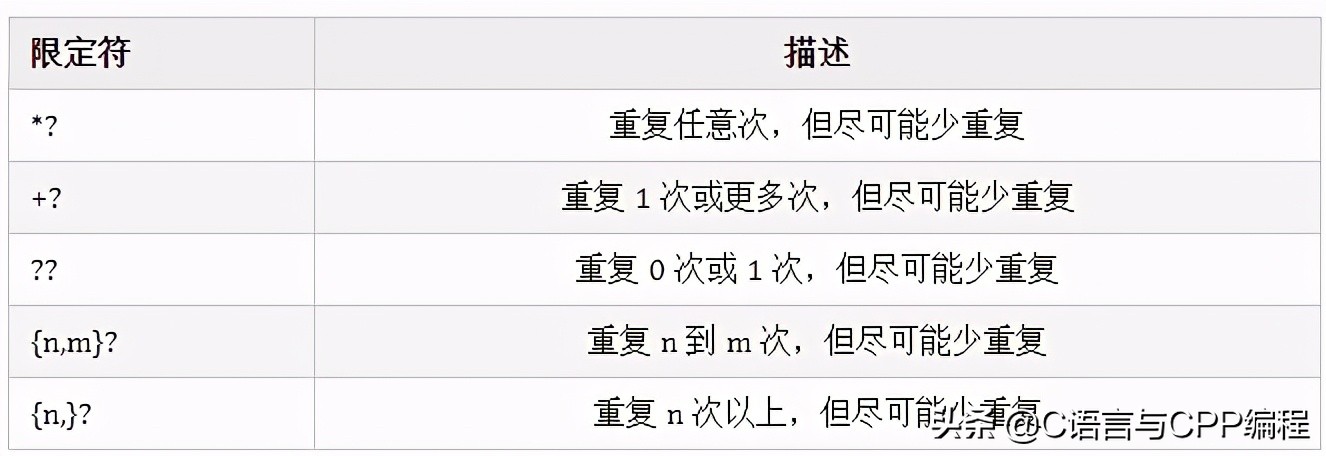
5、重复
已经看过了前面的 * , + 几个匹配重复的方式了。下面是正则表达式中所有的限定符(指定数量的代码:

6、字符类
要想查找数字、字母、数字、空白已经很简单,因为已经有了对应这些字符集合的元字符,但是如果你想匹配没有预定义元字符的字符集合(比如元音字母 a,e,i,o,u ),应该怎么办?
很简单,你只需要在方括号里列出它们就行了,像 [aeiou] 就匹配任何一个英文元音字母, [.?!] 匹配标点符号( . 或 ? 或 !)。
我们也可以轻松地指定一个字符范围,像 [0-9] 代表的含意与 d 就是完全一致的:一位数字;同理 [a-z0-9A-Z_] 也完全等同于 w (如果只考虑英文的话)。
下面是一个更复杂的表达式:(?0d{2}[) -]?d{8}。
这个表达式可以匹配几种格式的电话号码,像 011-22884499 ,或 0845652452 等。我们对它进行一些分析吧:首先是一个转义字符 (,它能出现 0 次或 1 次 (?),然后是一个 0,后面跟着 2 个数字 (d{2}),然后是)或-或空格中的一个,它出现 1 次或不出现(?),最后是 8 个数字(d{8})。
7、反义
有时需要查找不属于某个能简单定义的字符类的字符。比如想查找除了数字以外,其它任意字符都行的情况,这时需要用到反义
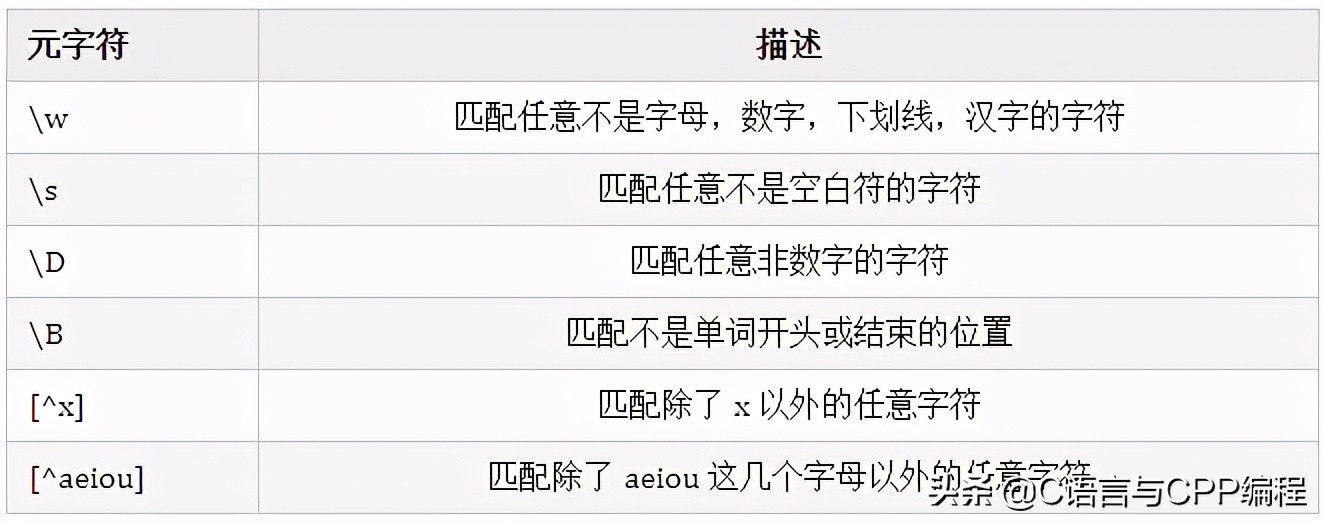
例子:
S+ 匹配不包含空白符的字符串。 <a[^>]+> 匹配用尖括号括起来的以 a 开头的字符串
8、分组
我们已经提到了怎么重复单个字符(直接在字符后面加上限定符就行了);但如果想要重复多个字符又该怎么办?可以用小括号来指定子表达式(也叫做分组),然后就可以指定这个子表达式的重复次数了,也可以对子表达式进行其它一些操作。
(d{1,3}.){3}d{1,3} 是一个简单的 IP 地址匹配表达式。要理解这个表达式,请按下列顺序分析它:d{1,3} 匹配 1 到 3 位的数字,(d{1,3}.){3} 匹配三位数字加上一个英文句号(这个整体也就是这个分组)重复 3 次,最后再加上一个一到三位的数字(d{1,3})。
可是也将匹配256.300.777.888这种不可能存在的 IP 地址。如果能使用算术比较的话,或许能简单地解决这个问题,但是正则表达式中并不提供关于数学的任何功能,所以只能使用冗长的分组,选择,字符类来描述一个正确的 IP 地址:((2[0-4]d|25[0-5]|[01]?dd?).){3}(2[0-4]d|25[0-5]|[01]?dd?)。
理解这个表达式的关键是理解2[0-4]d|25[0-5]|[01]?dd?,这里就不细说了,大家应该能分析得出来它的意义。
9、贪婪与懒惰
当正则表达式中包含能接受重复的限定符时,通常的行为是匹配尽可能多的字符。以这个表达式为例: b.*c ,它将会匹配最长的以 b 开始,以 c 结束的字符串。如果用它来搜索 babac 的话,它会匹配整个字符串 babac 。这被称为贪婪匹配。
有时,我们更需要懒惰匹配,也就是匹配尽可能少的字符。前面给出的限定符都可以被转化为懒惰匹配模式,只要在它后面加上一个问号 ? 。这样 .*? 就意味着匹配任意数量的重复,但是在能使整个匹配成功的前提下使用最少的重复。现在看看懒惰版的例子吧:
a.*?b 匹配最短的,以 a 开始,以 b 结束的字符串。如果把它应用于 aabab 的话,它会匹配 aab(第一到第三个字符)和 ab( 第四到第五个字符)。
10、处理选项
上面介绍了几个选项如忽略大小写,处理多行等,这些选项能用来改变处理正则表达式的方式。下面是 .Net 中常用的正则表达式选项:

一个经常被问到的问题是:是不是只能同时使用多行模式和单行模式中的一种?
答案是:不是。这两个选项之间没有任何关系,除了它们的名字比较相似(以至于让人感到疑惑)以外。
11、提示
正则表达式内容还有很多,笔者这里只列举常用部分,读者若想进一步学习,可在微软专业正则表达式学习网站学习:
正则表达式语法支持情况如下图:

相关推荐
-
北京地铁运营有限公司三分公司(三分公司最新消息)
一、运营三分公司简介 北京地铁运营三分公司是北京市地铁运营有限公司下属的二级分公司,公司位于德胜门正西方向约一公里处,毗邻北二环,公司现有员工7400余人,主要负责北京地铁2号线、…
-
ps怎样去水印,ps去水印常用的六种方法
九图网的朋友们大家好,去水印的工作相信在大家的日常工作中还是比较常遇到的。那么使用PS去水印怎么才能达到最好的效果呢。今天就给九图网的朋友们带来六种PS去水印的方法,希望对大家学习…
-
airpods蓝牙版本是多少,airpods蓝牙芯片是什么
第二代 AirPods 在上周正式开放预购,Apple 官方表示由于第二代 AirPods 采用的是 H1 芯片,能提供更快速、稳定的无线连接。然而Apple 没有告诉用户的是,实…
-
格力取暖器哪个型号好(格力取暖器型号推荐)
金秋十月在兜兜转转间悄然而过,走过霜降,尚存余温的大地真正是要披上寒衣,眼看着立冬与小雪纷至沓来。正是乍暖还寒时候,最难将息,几时风雨几时晴,晨起出门还披衣戴帽,午时却闷热脱衫;直…
-
果然汁己加盟费多少钱(早餐店加盟条件)
就在不少人为选择什么样的饮品而发愁时,果然汁己品牌为消费者提供了一个很好的解决方案。据记者调查,在饮品加盟排行榜上特立独行的果然汁己品牌,无疑是大家在冬季的最佳选择,也是可以四季畅…
-
营销策略有哪些方法(史上最全的13中靠谱的营销方案)
商品营销的成败不但与该商品的性能、质量、价格有关,与店铺的销售市场营销策略、销售方式等有着密切关系。 因此,质量和价格都很不错的商品,若销售市场营销策略不当,照样不被消费者所接纳;…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。