
阅读目录
- Myisam引擎(非聚集索引)
- Innodb引擎(聚集索引)
- 磁盘数据页的存储结构
- 主键索引页存储结构
什么是索引:
索引是一种高效获取数据的存储结构,例:hash、 二叉、 红黑。
Mysql为什么不用上面三种数据结构而采用B+Tree:
若仅仅是 select * from table where id=45 , 上面三种算法可以轻易实现,但若是select * from table where id<6 , 就不好使了,它们的查找方式就类似于”全表扫描”,因为他们的高度是不可控的(如下图)。B+Tree的高度是可控的,mysql通常是3到5层。注意:B+Tree只在最末端叶子节点存数据,叶子节点是以链表的形式互相指向的。
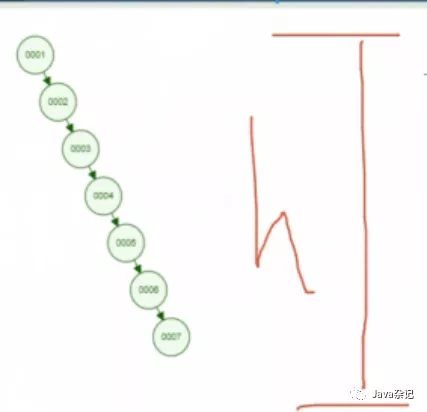

B+Tree的特性
(1)由图能看出,单节点能存储更多数据,使得磁盘IO次数更少。
(2)叶子节点形成有序链表,便于执行范围操作。
(3)聚集索引中,叶子节点的data直接包含数据;非聚集索引中,叶子节点存储数据地址的指针。
回到顶部
Myisam引擎(非聚集索引)
若以这个引擎创建数据库表Create table user (…..),它实际是生成三个文件:
user.myi 索引文件 user.myd数据文件 user.frm数据结构类型。
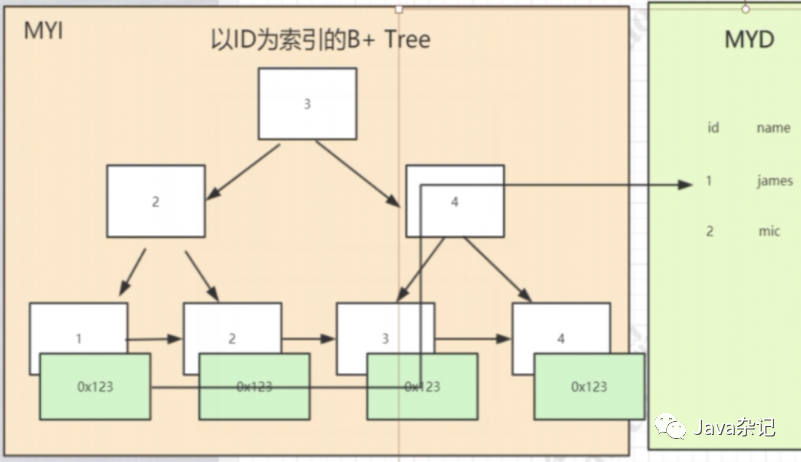
如下图:当我们执行 select * from user where id = 1的时候,它的执行流程。
(1)查看该表的myi文件有没有以id为索引的索引树。
(2)根据这个id索引找到叶子节点的id值,从而得到它里面的数据地址。(叶子节点存的是索引和数据地址)。
(3)根据数据地址去myd文件里面找到对应的数据返回出来。
回到顶部
Innodb引擎(聚集索引)
若以这个引擎创建数据库表Create table user (…..),它实际是生成两个文件:
user.ibd 表索引和数据文件 user.frm 表结构类型
因为innodb引擎创建表默认就是以主键为索引,所以不需要myi文件。
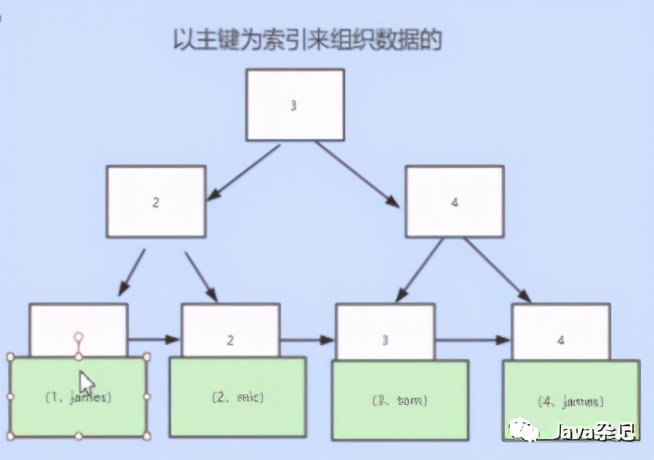
下图为innodb表的结构图:很显然它与myisam最大的区别是将整条数据存在叶子节点,而不是地址。(叶子节点存的是主键索引和数据信息)
若此时,你在其他列创建索引例如name,它就会另外创建一个以name为索引的索引树,(叶子节点存的是索引和主键索引)。
你在执行select * from user where name = ‘吴磊’,他的执行过程如下:
(1)找到name索引树
(2)根据name的值找到该树下叶子的name索引和主键值
(3)用主键值去主键索引树去叶子节点到该条数据信息
MyISAM引擎和InnoDB引擎的区别
MyISAM:支持全文索引;不支持事务;它是表级锁;会保存表的具体行数.
InnoDB:5.6以后才有全文索引;支持事务;它是星级锁;不会保存表的具体行数.
一般:不用事务的时候,count计算多的时候适合myisam引擎。对可靠性要求高就是用innodby引擎。推荐用InnoDB引擎.
加了索引之后能够大幅度地提高查询速度,但是索引也不是越多越好,一方面它会占用存储空间,另一方面它会使得写操作变得很慢。通常我们对查询次数比较频繁,值比较多的列才建索引。
例如:select * from user where sex = “女”, 这个就不需要建立索引,因为性别一共就两个值,查询本身就是比较快的。
select * from user where user_id = 1995 ,这个就需要建立索引,因为user_id的值是非常多的。
回到顶部
磁盘数据页的存储结构
磁盘中的数据页是按顺序一页一页存放的,然后两两相邻的数据页之间会采用双向链表的格式互相引用。每一行数据都会按照主键大小进行排序存储,同时每一行数据都有指针指向下一行数据的位置,组成单向链表。刚开始第一行是个起始行,他的行类型是2,就是最小的一行,然后他有一个指针指向了下一行数据,每一行数据都有自己每个字段的值,然后每一行通过一个指针不停地指向下一行数据,普通的数据行的类型都是0,最后一行是一个类型为3的,就是代表最大的一行。
我们刚说了,数据页中的数据行一定是按照主键大小正序排列的。下一页的主键也一定会比上一页的大。如果我们是自增还好,若是自己生成的则会出现顺序错乱情况。mysql则会通过页分裂的机制将数据挪动到上一个数据页,保证下一个数据页里的主键值都比上一个数据页里的主键值要大。
回到顶部
主键索引页存储结构
主键索引的目录结构,只要在一个主键索引里包含每个数据页跟他最小主键值,就可以组成一个索引目录。然后后续你查询主键值,就可以在目录里二分查找直接定位到那条数据所属的数据页,接着到数据页里二分查找定位那条数据就可以了。
现在问题来了,你的表里的数据可能很多很多,比如有几百万,几千万,甚至单表几亿条数据都是有可能的,所以此时你可能有大量的数据页,然后你的主键目录里就要存储大量的数据页和最小主键值,这怎么行呢?所以在考虑这个问题的时候,实际上是采取了一种把索引数据存储在数据页里的方式来做的。也就是我们上面提到的b+tree结构。
比如我现在要找id=45的数据,就会先从35页找到23页,再找到6页,最后找到第4页。然后它就指向了叶子节点(数据页)。
若是你基于非主键字段name 建立了一个索引,那么此时你插入数据的时候,就会重新搞一颗B+树,B+树的叶子节点也是数据页,但是这个数据页里仅仅放主键字段和name字段、数据行按name大小排列,就不是具体数据了。先找到name对应的主键地址,再去主键索引树找到具体数据信息。这种行为叫做回表查询(若select的所有字段都是索引中的字段则直接就返回了,不用去主键索引树中找了。这种行为叫做覆盖索引)
相关推荐
-
mysql添加用户并设置权限(mysql用户权限怎么设置)
1.登录本地用户 命令: 登录外网用户(需要注意服务器可能只允许本地登录,需要修改相应的配置文件) 配置文件是/etc/mysql/my.cnf 修改bind-address =1…
-
oracle迁移到mysql方案(oracle转mysql数据移植)
本文目录: 一、OGG概述 (一)OGG逻辑架构 二、迁移方案 (一)环境信息 (二)表结构迁移 (三)数据迁移 1.源端OGG配置 (1)Oracle数据库配置 (2)Oracl…
-
mysql数据库连接数过多如何释放(安全清理mysql数据内存的方法)
percona官方给mysql数据库提供了很多开源的工具,而且都非常好用,下面就先介绍一个杀会话的超强工具,比Mysql数据库自带的kill强太多,例如可以批量杀掉某个用户的会话,…
-
php操作mysql数据库函数(php连接mysql数据库代码)
有啥别有病,没啥别没钱,毕业这些年,我却掏不出给自己治病的钱。。。 —- 网易云热评 1、连接数据库 2、判断是否连接成功,连接失败返回false 3、数据库操作,增添…
-
oracle数据库正版多少钱(mysql安装教程)
甲骨文刚刚发布了 Oracle Linux 7.9,作为该公司最细推出的企业级 Linux 发行版更新,其引入了许多新功能和体验改进。据悉,Oracle Linux 7 的 Upd…
-
怎么安装mysql数据库(图解mysql数据库安装方法)
需要MySQL工具+教程请看下图: 单击进入后的主页如下: 然后单击downloads,community,然后选择MySQL Community Server。 如下图所示: 滑…
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。